अधिकांश समय, जब आपको एक्सेस ब्लॉक करने की आवश्यकता होती है SeekportBot या अन्य crawl bots एक वेबसाइट के साथ, कारण सरल हैं। वेब स्पाइडर कम समय में बहुत अधिक एक्सेस करता है और वेब सर्वर के संसाधनों का अनुरोध करता है, या यह एक सर्च इंजन से आता है जिसमें आप नहीं चाहते कि आपकी वेबसाइट इंडेक्स हो।
सी द्वारा देखी गई वेबसाइट के लिए यह बहुत फायदेमंद हैrawमैं उससे टकरा गया। इन वेब स्पाइडर को सर्च इंजन में वेब पेजों की सामग्री का पता लगाने, प्रोसेस करने और इंडेक्स करने के लिए डिज़ाइन किया गया है। Google और Bing ऐसे c का उपयोग करते हैंrawमैं उससे टकरा गया। हालाँकि, ऐसे सर्च इंजन भी हैं जो वेब पेजों से डेटा एकत्र करने के लिए रोबोट का उपयोग करते हैं। Seekport इन सर्च इंजनों में से एक है, जो c. का उपयोग करता हैrawवेब पेजों को अनुक्रमित करने के लिए सीकपोर्टबॉट लेर। दुर्भाग्य से, यह कभी-कभी इसका अत्यधिक उपयोग करता है और अनावश्यक ट्रैफ़िक बनाता है।
कपि ins
सीकपोर्टबॉट क्या है?
SeekportBot एक है web crawler कंपनी द्वारा विकसित Seekport, जो जर्मनी में स्थित है (लेकिन फ़िनलैंड सहित कई देशों के IP का उपयोग करता है)। इस बॉट का उपयोग वेबसाइटों को क्रॉल और इंडेक्स करने के लिए किया जाता है ताकि उन्हें सर्च इंजन परिणामों में प्रदर्शित किया जा सके। Seekport. जहां तक मैं कह सकता हूं, एक गैर-कार्यात्मक खोज इंजन। कम से कम, इसने मेरे लिए किसी भी प्रमुख वाक्यांश के लिए कोई परिणाम नहीं दिया।
SeekportBot उपयोगों user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"सीकपोर्टबॉट या अन्य सी तक पहुंच को कैसे अवरुद्ध करेंrawमैंने एक वेबसाइट पर क्लिक किया
यदि आप इस निष्कर्ष पर पहुंचे हैं कि यह वेब स्पाइडर या अन्य, आपकी पूरी वेबसाइट को स्कैन करना और वेब सर्वर पर अनावश्यक ट्रैफ़िक बनाना आवश्यक नहीं है, तो आपके पास कई तरीके हैं जिनसे आप उनकी पहुँच को रोक सकते हैं।
वेब सर्वर स्तर पर फ़ायरवॉल
वे फ़ायरवॉल अनुप्रयोग हैं open-source जिसे ऑपरेटिंग सिस्टम पर इंस्टॉल किया जा सकता है Linux और कई मानदंडों के आधार पर यातायात को अवरुद्ध करने के लिए कॉन्फ़िगर किया जा सकता है। आईपी पता, स्थान, बंदरगाह, प्रोटोकॉल या उपयोगकर्ता एजेंट।
APF (Advanced Policy Firewall) एक ऐसा सॉफ्टवेयर है जिसके जरिए आप सर्वर लेवल पर अनचाहे बॉट्स को ब्लॉक कर सकते हैं।
क्योंकि सीकपोर्टबॉट और अन्य वेब स्पाइडर आईपी के कई ब्लॉक का उपयोग करते हैं, सबसे प्रभावी ब्लॉकिंग नियम "पर आधारित है।user agent"। इसलिए, यदि आप एक्सेस को ब्लॉक करना चाहते हैं SeekportBot की मदद से APF, आपको बस इतना करना है कि वेब सर्वर से कनेक्ट करना है SSH, और कॉन्फ़िगरेशन फ़ाइल में फ़िल्टर नियम जोड़ें।
1. कॉन्फ़िगरेशन फ़ाइल को खोलें nano (या अन्य प्रकाशक)।
sudo nano /etc/apf/conf.apf2. उस रेखा को देखें जो “से शुरू होती हैIG_TCP_CPORTS” और उस उपयोगकर्ता एजेंट को जोड़ें जिसे आप इस पंक्ति के अंत में ब्लॉक करना चाहते हैं, उसके बाद अल्पविराम। उदाहरण के लिए, यदि आप ब्लॉक करना चाहते हैं user agent "SeekportBot", रेखा इस तरह दिखनी चाहिए:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. फ़ाइल सहेजें और APF सेवा को पुनरारंभ करें।
sudo systemctl restart apf.service"सीकपोर्टबॉट" पहुंच अवरुद्ध हो जाएगी।
फ़िल्टर web crawls Cloudflare की मदद से – SeekportBot की एक्सेस को ब्लॉक करें
क्लाउडफ्लेयर की मदद से, यह मुझे सबसे सुरक्षित और सबसे सुविधाजनक तरीका लगता है जिसके द्वारा आप कुछ बॉट्स की पहुंच को विभिन्न तरीकों से एक वेबसाइट तक सीमित कर सकते हैं। जिस तरीके का मैंने केस में भी इस्तेमाल किया SeekportBot किसी ऑनलाइन स्टोर के ट्रैफ़िक को फ़िल्टर करने के लिए।
यह मानते हुए कि आपके पास पहले से ही क्लाउडफ्लेयर में वेबसाइट जोड़ी गई है और डीएनएस सेवाएं सक्रिय हैं (अर्थात वेबसाइट का ट्रैफिक क्लाउडफ्लेयर से होकर जाता है), नीचे दिए गए चरणों का पालन करें:
1. अपना क्लॉफ्लेयर अकाउंट खोलें और उस वेबसाइट पर जाएं जिसके एक्सेस को आप सीमित करना चाहते हैं।
2. यहां जाएं: Security → WAF और एक नया नियम जोड़ें। Create rule.
3. नए नियम के लिए एक नाम चुनें, Field: User Agent - Operator: Contains - Value: SeekportBot (या अन्य बॉट नाम) – Choose action: Block - Deploy.
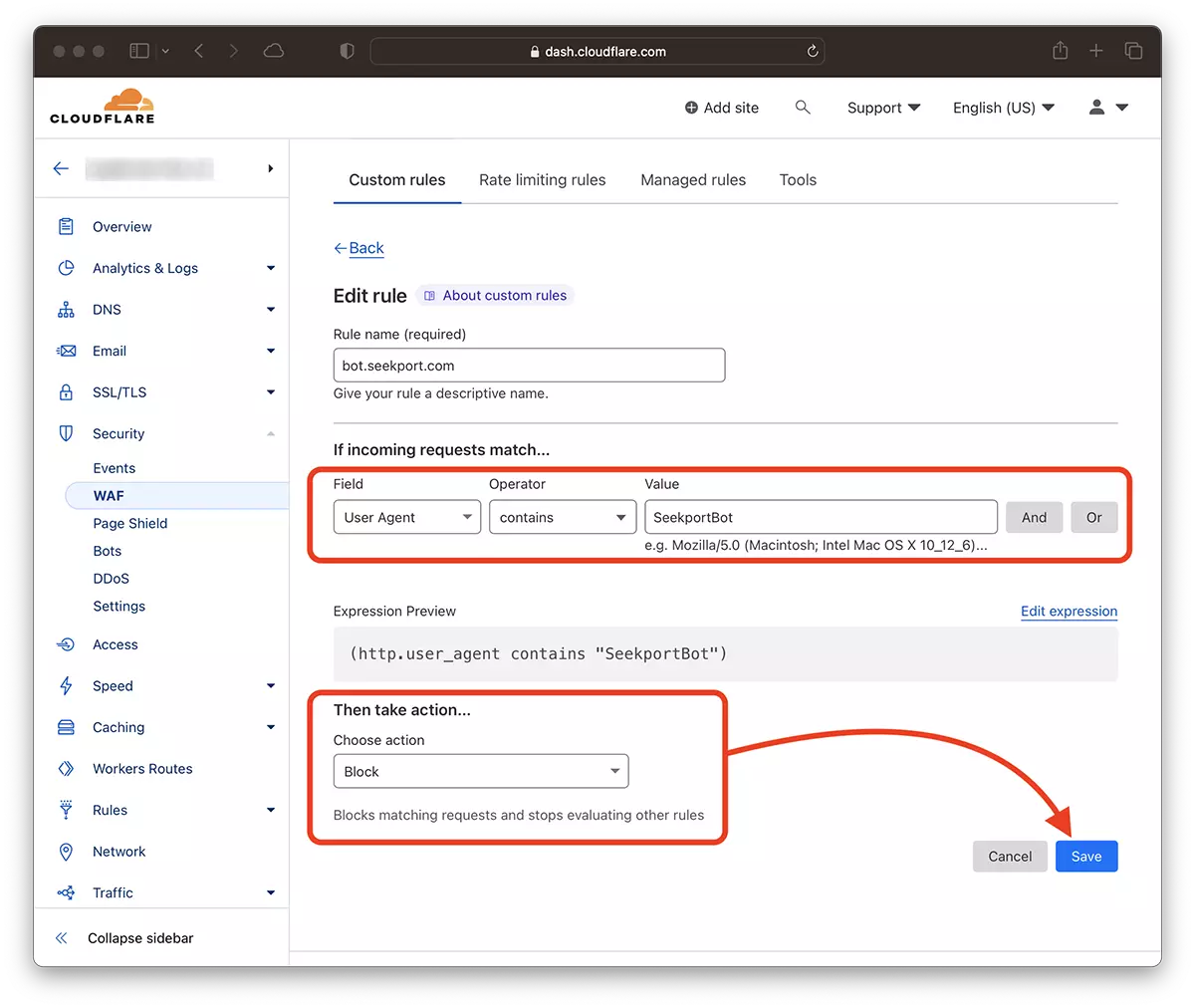
कुछ ही सेकंड में, नया नियम WAF (Web Application Firewall) इसका असर होने लगता है।
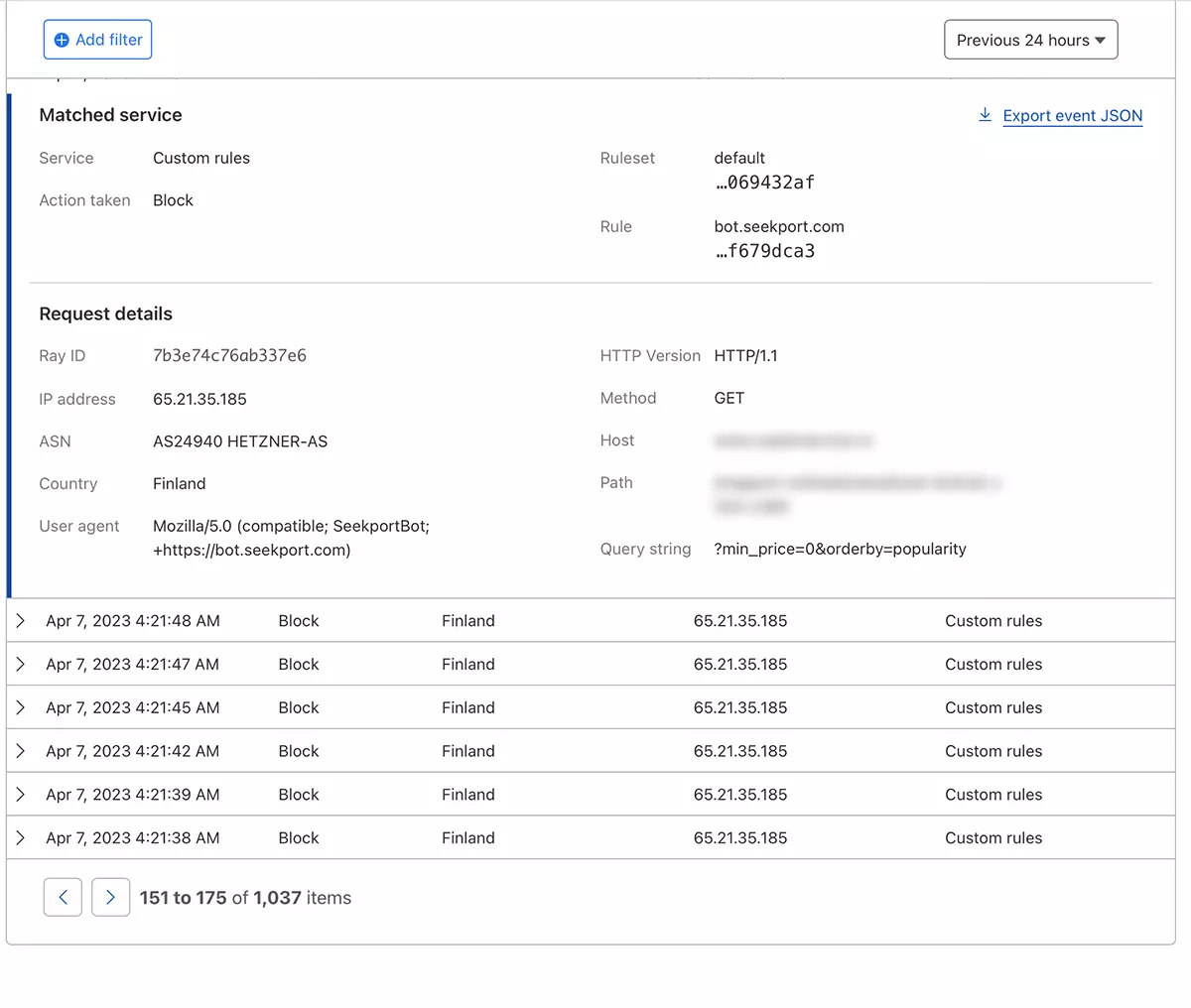
सिद्धांत रूप में, वह आवृत्ति जिसके साथ एक वेब स्पाइडर किसी साइट तक पहुँचता है, से सेट किया जा सकता है robots.txt, लेकिन... यह केवल सिद्धांत में है।
User-agent: SeekportBot
Crawl-delay: 4अनेक web crawlerii (बिंग और गूगल को छोड़कर) इन नियमों का पालन नहीं करते हैं।
अंत में, यदि आप एक वेब सी की पहचान करते हैंrawl जो आपकी साइट को अत्यधिक एक्सेस करता है, उसकी एक्सेस को पूरी तरह से ब्लॉक करना सबसे अच्छा है। बेशक, अगर यह बॉट किसी सर्च इंजन से नहीं है जिसमें आप उपस्थित होने में रुचि रखते हैं।